GroupGEMM算子优化¶
背景¶
混合专家(Mixture of Experts, MoE)架构已成为扩展大规模语言模型的重要范式,其核心思想是将输入token动态路由至不同的专家子网络进行处理。在推理过程中,GroupGEMM算子是MoE架构的关键计算单元,负责高效执行多个专家矩阵乘法的并行计算,且在整个推理耗时中占据主导地位。
功能介绍¶
结合当前GroupGEMM的性能瓶颈为I/O受限,提出了一种优化方案,通过索引重排替代数据拷贝,取消了对token向量的多次复制,改为维护专家分配的索引表。通过该行号索引,直接将token映射到相应的专家计算单元,并将token的分配调度与矩阵乘法融合为一个单一的kernel。
用户接口¶
算子直调API¶
aclnnStatus aclnnIndexGroupMatmulGetWorkspaceSize(
const aclTensorList *x,
const aclTensorList *weight,
const aclTensorList *scale,
const aclTensorList *perTokenScale,
const aclTensor *groupList,
const aclTensorList *out,
uint64_t *workspaceSize,
aclOpExecutor **executor);
aclnnStatus aclnnIndexGroupMatmul(
void *workspace,
uint64_t workspaceSize,
aclOpExecutor *executor,
aclrtStream stream);
x: 输入的张量列表,包含待处理的数据。weight: 权重张量,包含模型的参数。scale: 缩放因子,用于调整输入张量的值。perTokenScale:每个token的缩放因子,用于动态调整。groupList: 专家组列表,指示哪些专家参与计算。out: 输出张量列表,存储计算结果。
性能效果¶
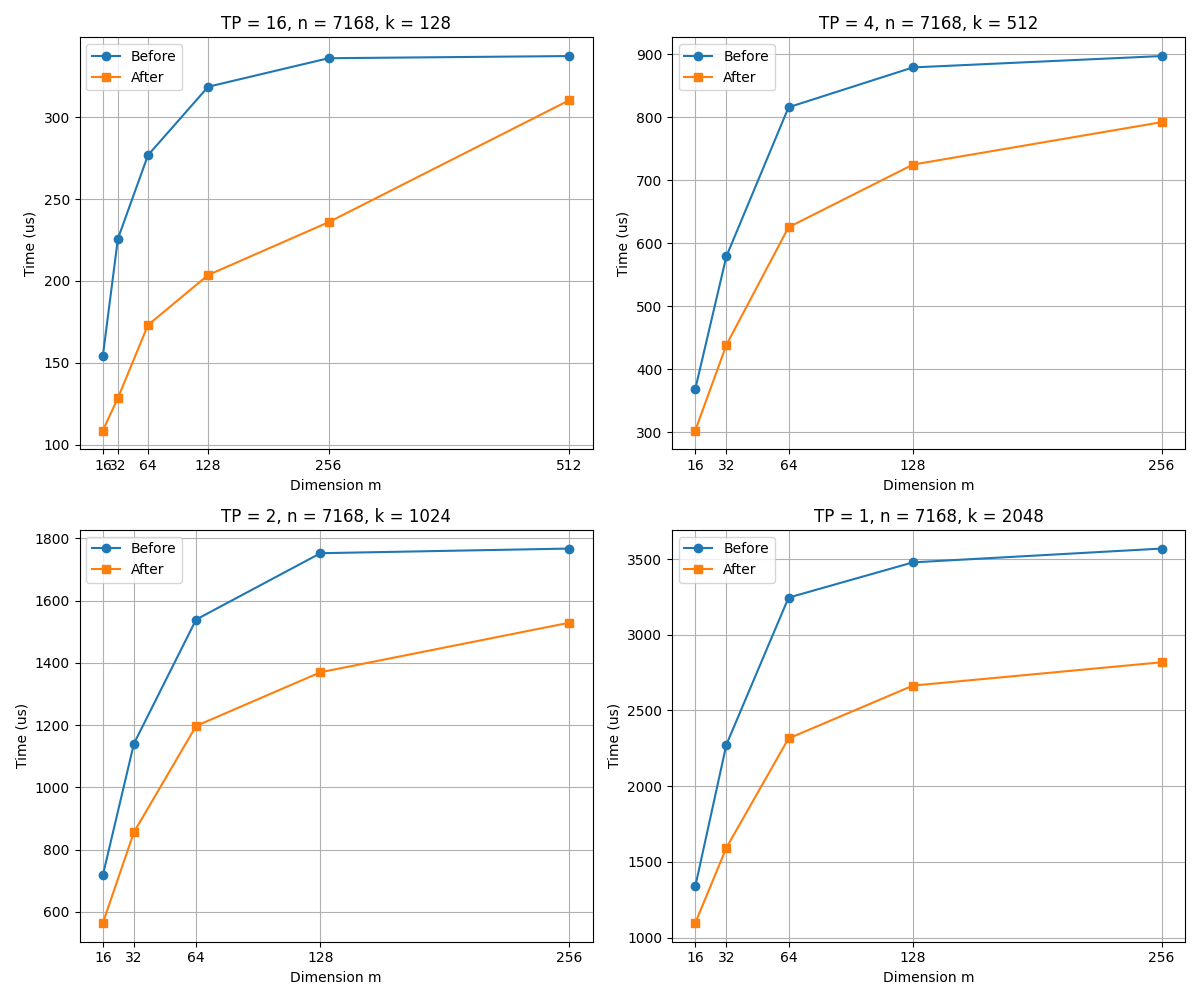
- 优化后的GroupMatmul算子在计算时间上表现出明显的优势,尤其是在k为128,m为64情况下,如图所示,优化后算子计算延时 减少50%。